Select text.
Improve it instantly.
Avelyn lives in your menu bar. Highlight anywhere, hit your shortcut, and let local AI rewrite, refine, and perfect your text.
Everything you need.
Nothing you don't.
Absolute Privacy.
100% Local AI.
Your data never leaves your physical memory. Harness Llama 3, Gemma, or Mistral natively via Ollama with zero cloud processing and zero telemetry.
Lightning Fast
Highlight any text, anywhere. Hit Ctrl+Shift+E and Avelyn replaces it instantly.
Context Aware
Automatically detects your tone and intent to generate structural adjustments that feel human.
Polished Prose
Fix awkward phrasing, upgrade your vocabulary, and tighten sentences for maximum impact.
Universal Integration
Functions flawlessly across VS Code, Chrome, Word, Slack, Notion, and literally any editable text interface system-wide.
Auto-Prompts
Transform basic instructions into highly optimized prompt structures instantly.
Silent Fixes
Correct spelling, fix complex syntax, and enforce formatting rules in the background.
See the Workflow in Action
01.Highlight Any Text Block
Select the text you want to rewrite or enhance. Works natively across Safari, Chrome, Slack, Notion, Word, and VS Code without any extensions.
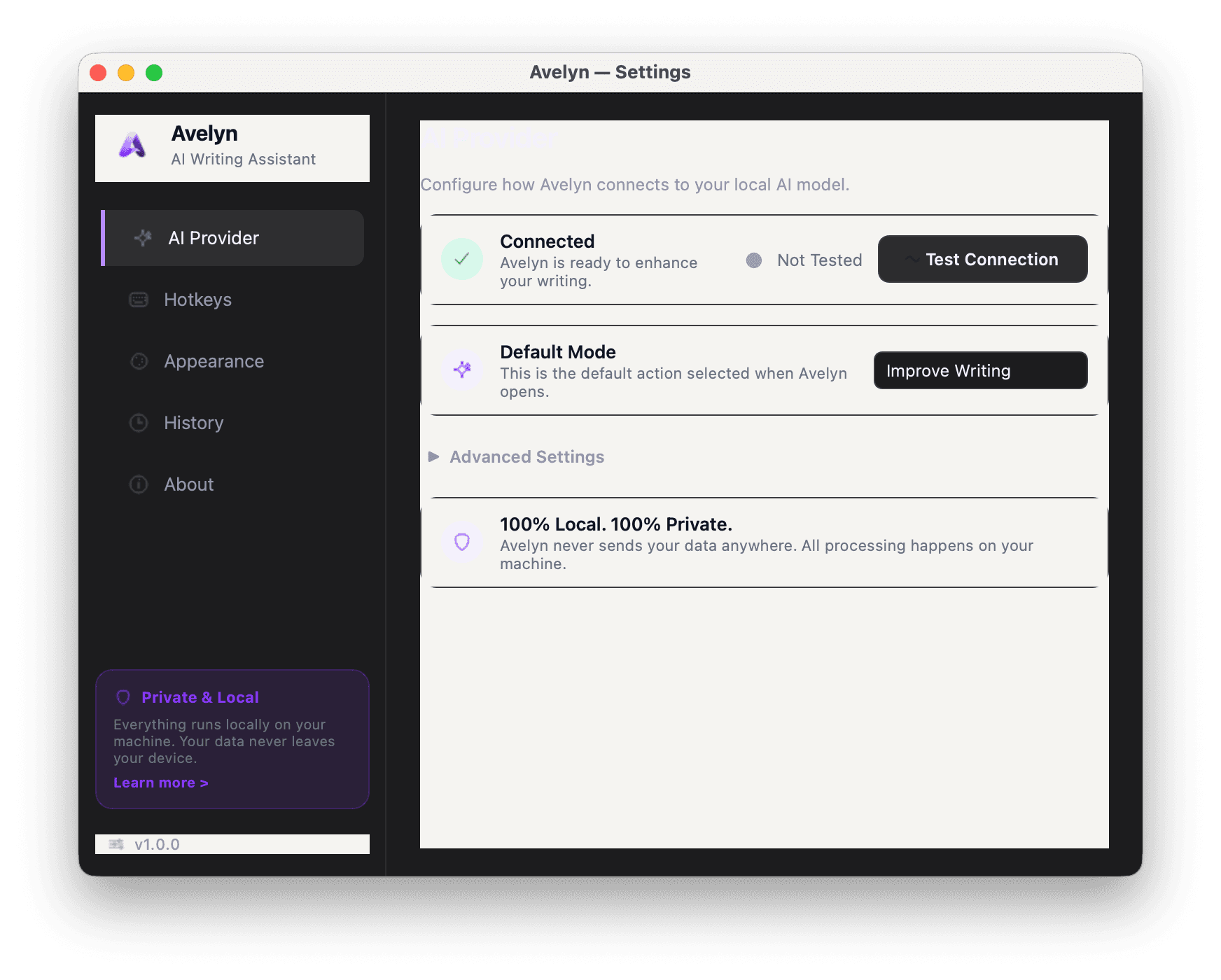
Feels like it belongs
on your Mac.
Take a closer look at the actual product layout, designed to blend seamlessly with macOS Sonoma & Sequoia.
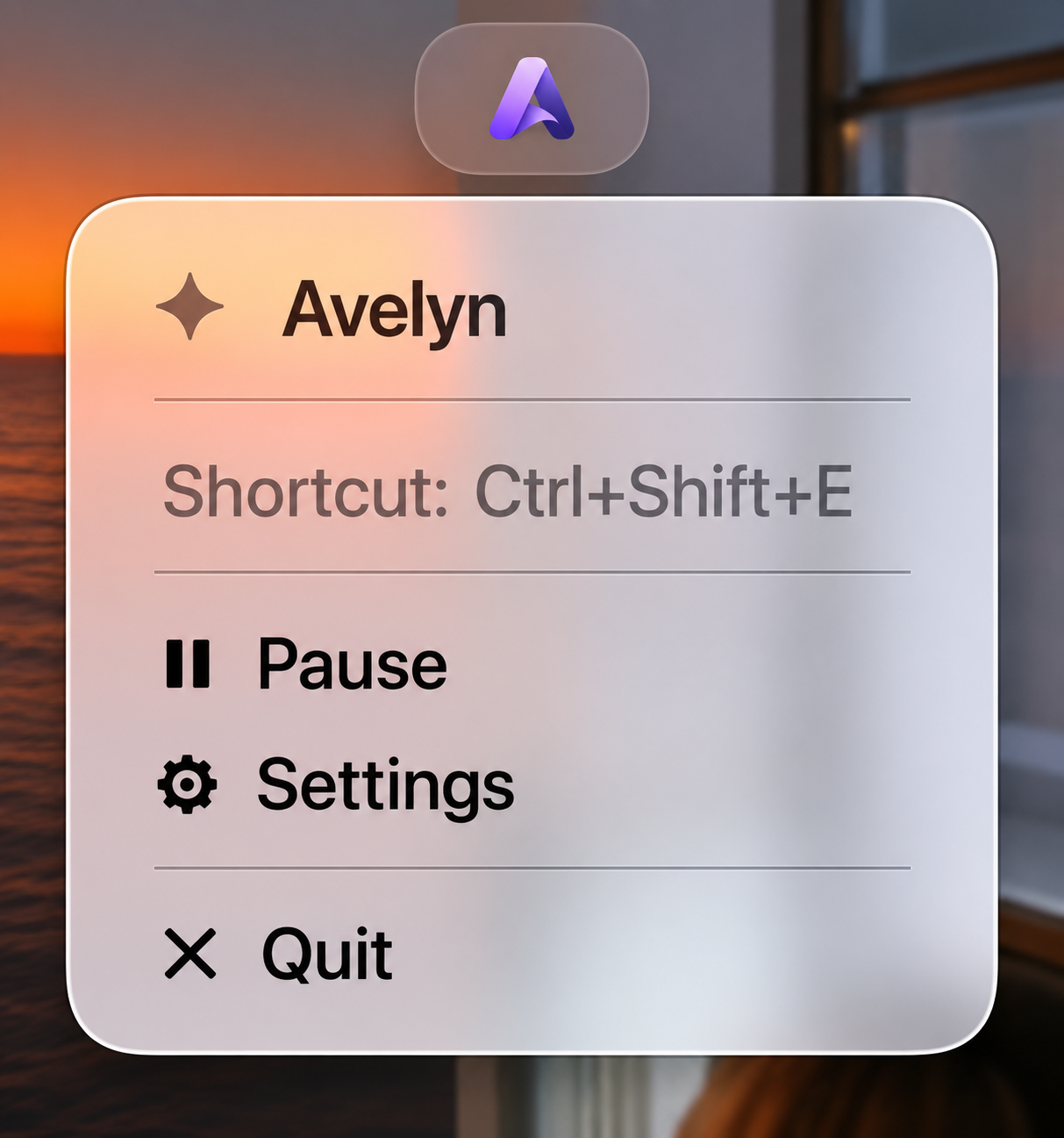
Zero-Intrusion
Menu Bar Experience
Avelyn operates entirely in the background, living in your macOS Menu Bar. Trigger it with a keystroke, adjust settings in two clicks, and keep your screen 100% focused on your actual work.
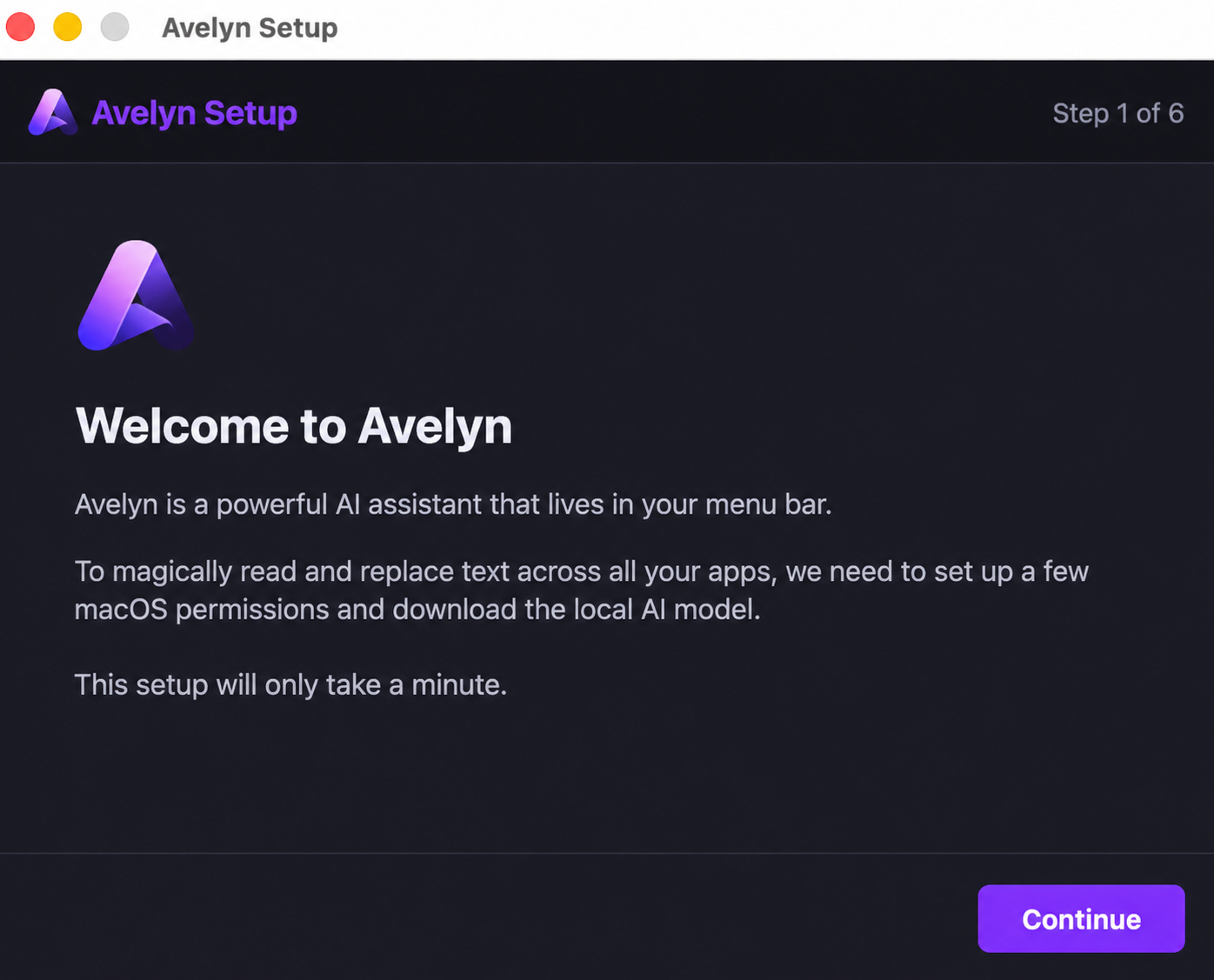
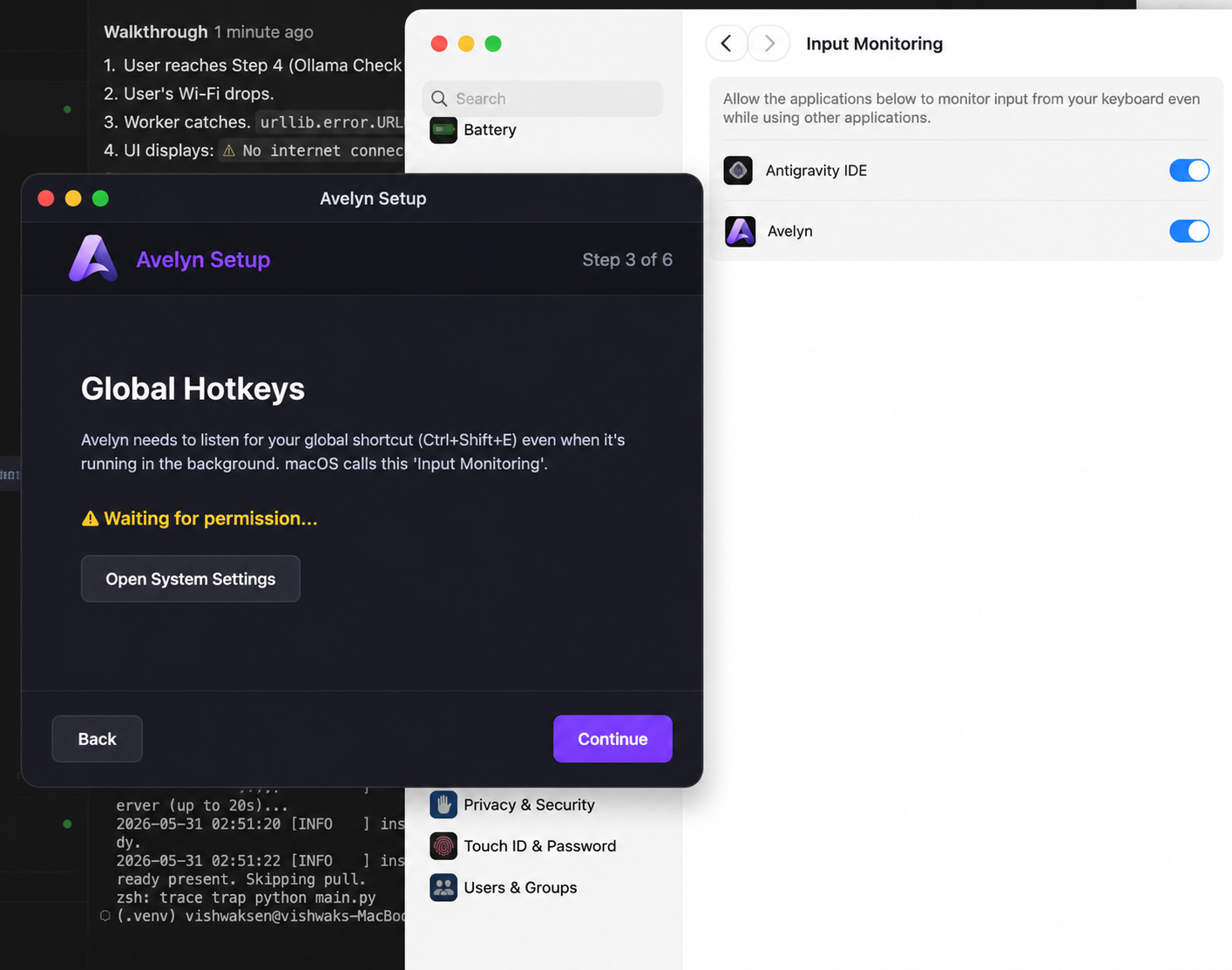
First-Run
Setup Wizard
Getting started with local offline AI should be simple. A premium, step-by-step setup wizard guides you perfectly through model selection and global hotkey preferences.
Self-Healing
Permission Assistant
No more troubleshooting terminal commands. Avelyn features a native helper to assist you with macOS Accessibility and Input permissions so global paste events function securely.
Your data stays
strictly on your machine.
Modern AI tools depend on cloud pipelines that log, inspect, and train on your private thoughts. Avelyn turns this model on its head by computing everything locally.
Zero Telemetry
Your selected text and clipboard history never touch external databases, trackers, or telemetry pipelines. Complete digital anonymity.
100% Offline
Run inference entirely offline without active internet connections. Essential for high-security workplace policies and air-gapped systems.
Local Acceleration
Runs strictly locally utilizing Apple Silicon Unified Memory or Windows Nvidia RTX cores. Blazing-fast generation without server wait times.
Frequently Asked
Questions
Yes, 100%. When configured with Ollama (Local Offline), Avelyn performs all LLM calculations locally on your CPU or GPU without requiring any active internet connection.
Experience the
future of writing.
We are running a limited-enrollment private beta to polish offline performance and native macOS window mechanics. Request your access token below.
v1.0.0-beta4
Sonoma & Sequoia window focus stability patches deployed.
v1.1.0-RC1
Local Ollama token streaming speed increased by ~25%.
"Completely replaces web dashboards for me."
Having a local, offline assistant that lives natively inside the macOS clipboard stack is a game-changer. The inference latency on Apple Silicon is extremely impressive.